들어가며...
AI 기술이 우리 사회 곳곳에 스며들면서 관련 법과 제도의 필요성이 부쩍 제기되고 있다. 최근 크게 논란이 되었던 AI 챗봇 이루다 사건은 전 국민이 AI 윤리를 고민하는 계기가 됐다.
법무법인 태평양과 공동 기획한 연재 칼럼에서는 변호사 관점에서 최신 AI 법·제도·윤리 이슈를 분석한다. 법무법인 중 국내 최초로 AI팀을 꾸린 태평양 내 AI 전담 변호사들이 AI가 사회 속에 자연스레 녹아들어갈 방법과 실제적인 해결책을 모색한다.
②대규모 언어모델의 등장과 위험 기반의 AI 거버넌스

대규모 언어모델의 등장
최근 국내 유수 IT 기업들이 대규모 언어모델 개발 계획을 발표하고 있다. 이에 작년에 출시된 GPT-3 모델이 전세계에 선사한 충격을 국내에서도 경험할 수 있을 것이라는 기대감이 커지고 있다. 하지만 기대만큼이나 언어모델을 비롯한 대규모 AI 모델이 우리 사회에 미칠 영향에 대해서도 주의를 기울일 필요가 있다.
언어모델은 단어에 확률 값을 부여하여 이를 통해 주어진 문장 배열에서 다음 단어를 예측하거나 생성하는 통계 모델이다. 직관적으로 설명하면, 언어모델은 통계적으로 가장 자연스러운 단어들의 조합을 찾아내어 문장을 만들어 내는 모델이라고 할 수 있다. 최근 많은 주목을 받고 있는 대규모 언어모델들은 테라 바이트(Tera Byte) 단위의 대용량의 말뭉치를 통해 모델을 학습시켜 사람이 쓴 것 같은 복잡한 문장들을 생성해낼 수 있다. 사람과 같이 기사를 쓰거나 대화를 자연스럽게 이어 나가는 서비스가 대표적인 대규모 언어모델에 기반한 AI 서비스들이다.
대규모 언어모델의 작동 방식
대규모 언어모델의 대표적인 예로 GPT 모델(Generative Pre-Training Model)이 있다. 대규모 언어모델의 출력 내용만 보면 마치 학습에 사용된 말뭉치를 그대로 모델 내에 저장하여 그때 그때 그대로 꺼내 쓰는 것으로 이해할 수 있지만 실제 작동 방식은 그렇지 않다.
GPT 모델의 경우, 말뭉치 문장을 작은 단위의 단어로 토큰화하여, 각 단어와 단어 사이의 통계적 상관관계를 학습한다. 가령 학습 말뭉치 속에 “오늘 식사는 맛있었다”라는 문장이 있다면, 이를 “오늘, 식사, 는, 맛있, 었, 다”로 쪼개어 각 단어들의 관계를 학습하는 것이다.
이처럼 학습된 모델은 주어진 단어에 대해 통계적으로 가장 적합한 다음 단어를 생성해낼 수 있다. 즉 토큰화된 단어들을 재료로 하여 새로운 문장이나 표현을 만들어내는 것이다. 가령 모델이 학습한 데이터 속에 “종로구 공평동”과 “강남구 압구정동”이라는 표현이 있다면, 위 표현을 쪼갠 후 다시 조합해 “종로구 압구정동”이라는 표현을 출력한다. 이처럼 GPT 모델은 대부분의 경우 학습에 사용된 실제 정보가 아닌 '가짜 정보'를 출력한다.
데이터 암기와 학습데이터 추출 공격
그런데 최근 GPT 계열의 2세대 모델인 GPT-2 모델이 학습 말뭉치 속 표현을 일부 그대로 암기하고, 모델에 적절한 문구를 입력하면 모델이 암기한 표현을 추출할 수 있다는 연구 결과가 공개돼 사람들의 주목을 끌었다(Carlini et al (2020) “Extracting Training Data from Large Language Models”). 가령 GPT-2 모델에 "East Stroudsburg Stroudsburg"라는 문구를 입력하면, 학습 말뭉치에 포함되어 있었던 실제 사람의 이름, 이메일 주소 등의 개인정보가 출력된다는 것이다
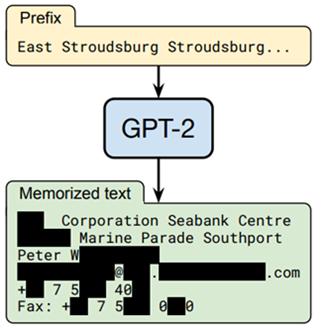
위 논문의 필자들은 오픈AI(OpenAI)가 학습해 공개한 GPT-2 모델을 대상으로 학습데이터 추출 공격을 시도했다. 그 결과 GPT-2 모델이 생성한 문장 60만 건 중 604건이 학습 말뭉치에 있었던 문장이라는 사실을 알아냈다(전체 생성 문장의 0.1%). 이 중 78건에는 사람 이름 및 연락처 정보 등 개인정보가 포함됐다(전체 생성 문장의 0.013%).
사실 AI 모델이 학습데이터에 포함된 개별 데이터들을 암기하는 현상은 머신러닝 기반 AI 모델에서 공통적으로 확인할 수 있는 현상이다. 이는 주로 모델 학습 시 과적합(Overfitting)으로 인해 발생하는데, 마치 학생이 학교 시험 점수를 높이기 위해 교과서 예제 풀이 방법을 이해하는 대신 문제와 답을 통째로 외우려고 하는 것과 같다. 즉 AI 모델도 학습 과정에서 학습데이터를 대상으로 높은 성능을 보이기 위해 특정 데이터를 암기해 버리는 것이다.
문제는 만약 AI 모델이 암기한 데이터 안에 개인정보가 포함돼 있을 경우, 외부 공격자가 그 모델로부터 개인정보를 추출할 위험이 발생한다는 점이다. 과거 안면 인식 AI 시스템을 대상으로 학습데이터에 포함된 사람의 얼굴 사진을 복원하여 추출할 수 있다는 사실이 논문을 통해 발표되기도 했다(Fredriksen et al (2015) “Model Inversion Attacks that Exploit Confidence Information”).

대규모 언어모델의 경우 지금까지 과적합이 일어날 가능성이 낮아서 학습데이터 암기 및 추출의 위험이 없거나 매우 낮다고 알려져 있었다. 하지만 이제 대규모 언어모델에서도 학습데이터 추출이 가능하다는 것이 실증적으로 밝혀진 것이다.
대규모 언어모델의 특성과 규제의 필요성
현재 학습데이터 추출 공격을 방지하기 위한 다양한 방법들이 연구되고 있다. 학습데이터에서 개인정보를 삭제 또는 다른 정보로 치환하는 방법, 차분 프라이버시(Differential Privacy) 개념을 적용하는 방법 등이 대표적이다. 하지만 갈수록 대용량의 말뭉치나 이미지와 같은 비정형데이터가 AI 모델 학습에 활용되고 있는 상황에서 현재 기술 수준으로 학습데이터에 포함된 개인정보를 100% 삭제한다는 것은 불가능에 가깝다.
그렇다면 최근 연구가 활발하게 이뤄지고 있는 대규모 언어모델들이 학습데이터에 포함된 개인정보를 암기해 출력한다면 현행법상 어떤 문제가 발생할 수 있을까. 물론 학습데이터가 공개된 정보로만 구성돼 있는지 아니면 비공개 정보도 포함하는지 여부나 학습데이터에 포함된 개인정보의 성격 등에 따라 다르게 볼 부분이 있다. 하지만 원칙적으로 개인정보보호법상 개인정보 유출이나 개인정보의 목적 외 이용에 해당할 가능성이 있다. 법의 잣대를 적용하기 전에 대규모 언어모델 특성을 되짚어 봐야 한다.
대규모 언어모델은 애초에 현실 세계에서 사람들이 사용하는 언어를 학습해 실제 사람이 쓴 것과 같은 그럴듯한 문장을 생성하기 위한 AI 모델이다. 즉 '가짜 문장', 더 나아가 '가짜 개인정보'를 생성하는 데에 특화된 모델인 것이다.
실제로 앞서 본 GPT-2 모델의 경우 암기된 문장은 전체 생성 문장의 0.1%에 불과했고 나머지 99.9%는 새롭게 가공된 문장이었다. 실제 개인정보가 포함된 문장은 전체 생성 문장의 0.013%에 불과했는데, 만약 학습데이터 내 개인정보에 대해 비식별화 조치를 한다면 그 확률은 더욱 낮아질 것이다. 따라서 일반 사람들은 대규모 언어모델이 생성한 문장만 봐서는 그 안에 포함돼 있는 개인정보가 학습 말뭉치 속 진짜 정보인지 아니면 모델이 생성해낸 가공의 정보인지 알 수가 없다.
더욱이 대규모 언어모델이 생성한 정보가 암기된 정보인지 여부를 알기 위해서는 통계적인 분석 과정이 필요한데 이러한 전문적인 과정을 거치더라도 특정 정보가 암기된 정보인지 여부는 '확률 값'으로만 확인할 수 있다. 따라서 모델로부터 개인정보를 추출한 경우 그 정보를 실제 학습데이터와 대조하기 전에는 그 정보가 실제 개인정보에 해당하는지 여부를 100% 확신할 수 없다.
이처럼 대규모 언어모델이 생성한 개인정보가 실제 개인정보에 해당하는지 식별하기 어렵고 그로 인해 정보주체에게 위해가 발생할 가능성이 낮다면, 개인정보가 추출될 위험이 존재한다는 사실만으로 위법으로 판단해 제재를 하거나 사용을 금지해서는 안 될 것이다.
위험 기반 접근 방식의 필요성
반대로 언어모델 중에서 높은 확률로 암기된 개인정보를 그대로 출력하는 모델을 가정해보자. 이처럼 위험이 높은 모델에 대해서는 규제 적용에 있어 앞서 본 사례와는 다른 접근을 할 필요가 있을 것이다. 그렇다면 두 경우를 어떤 방식으로 구분하여 다른 잣대를 적용할 수 있겠는가.
불확실성이 내재한 AI 모델에 대해 유연하게 대응하기 위해서는 AI 모델이 발생하는 위험의 정도에 따라 규제를 적용하는 '위험 기반 접근' 방식이 필요하다. 이를 통해 위험이 경미한 AI 모델의 경우 규제 적용을 자제함으로써 사업자가 시장에 안착하고 자발적으로 위험 요소를 시정할 기회를 가질 수 있도록 해야 한다. 이후 추가 위험이 발견되거나 위험의 증가 사실이 확인될 경우 규제 여부를 재검토하는 방향으로 접근하는 것이 바람직하다. 위험 기반 접근 방식은 AI가 우리 사회에 가져올 수 있는 혁신과 위험을 균형 있게 수용하기 위한 유용한 수단이 될 것이다.
법무법인 태평양 마경태 변호사 kyungtae.ma@bkl.co.kr
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com